


Machine Learning applicato al rilevamento dei danni alle strutture
Il Machine Learning, sottoinsieme dell’Intelligenza Artificiale, trova applicazione nell’ingegneria strutturale per l’analisi predittiva del degrado. Tecniche automatizzate e rilievi da drone promettono di affiancare o sostituire le ispezioni tradizionali, migliorando sicurezza, efficienza e precisione.
Sebbene siano correlati e molto spesso vengano utilizzati come sinonimi, l’Intelligenza Artificiale ed il Machine Learning non sono la stessa cosa. L’Intelligenza Artificiale è una branca dell’informatica che studia la progettazione di sistemi intelligenti capaci di imitare il comportamento del pensiero umano. Invece il Machine Learning (in italiano apprendimento automatico) è un sottoinsieme applicativo dell’Intelligenza Artificiale: esso rappresenta una forma di intelligenza artificiale che impara a migliorare se stessa senza la necessità di ricevere istruzioni esplicite dall’essere umano.
Questo tipo di apprendimento può essere utilizzato in diversi campi, tra cui l'ingegneria strutturale, per analizzare e prevedere il comportamento delle strutture. In particolare, il Machine Learning può essere utilizzato per sviluppare modelli di rilevamento automatico del degrado e del danno nei ponti, che possono supportare i tecnici nella valutazione delle condizioni delle strutture e in futuro rimpiazzare - ad esempio con l’ausilio di rilievi eseguiti da droni - un processo faticoso, pericoloso, costoso e soggetto a errori come le ispezioni tradizionali.
I sottoinsiemi dell’Intelligenza Artificiale
Nel Supervised Learning (in italiano apprendimento supervisionato) vengono implementati dati di input (cosiddetto dataset) ai quali vengono associati rispettivi output desiderati. Il fine è costruire un modello predittivo sulla base di una regola generale “estratta” dai dati che sia in grado di associare l’input all’output corretto. L’architettura di un modello di apprendimento automatico supervisionato prende il nome di rete neurale artificiale: essa riproduce le modalità in cui i neuroni si inviano i segnali; la sua etimologia è infatti ispirata dal cervello umano.
Il Deep Learning (in italiano apprendimento profondo) è un sottoinsieme del Machine Learning nel quale il processo di estrazione delle caratteristiche risulta quasi totalmente automatizzato e non necessita dell’intervento umano, se non in piccola parte.
Le reti neurali convoluzionali sono particolari reti neurali artificiali, algoritmi di Deep Learning composti da una serie di moduli con dei filtri: la rete trasforma un’immagine di input in valori di probabilità delle singole classi presenti nell’immagine stessa (fig. 1).
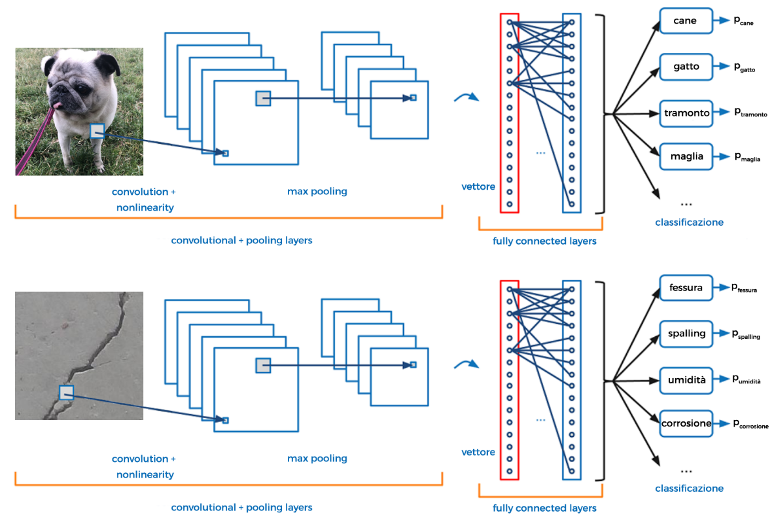
Sono particolarmente adatte per il riconoscimento di oggetti nelle immagini e nei video. L’interpretazione del contenuto delle fotografie (fig. 2) è denominata computer vision (visione artificiale).

Aspetti computazionali del modello di rilevamento automatico
Per la creazione di un modello di rilevamento automatico del degrado e del danno nei ponti in c.a. e c.a.p. si sono sfruttate le potenzialità del deep learning e del supervised learning, con il fine di classificazione. Per poter rilevare più fenomeni di degrado e danno è necessaria l’istituzione di un modello di object detection (rilevamento di oggetti) attraverso una classificazione multiclasse: in questo caso applicativo l’obiettivo finale non è rilevare la presenza di un determinato tipo di danno o meno (danno sì – danno no; scopo invece di una classificazione binaria) bensì quello di rilevare e ovviamente di classificare più tipi di difetti.
Il linguaggio di programmazione utilizzato per la realizzazione del modello è Python, noto per la sua dinamicità, facilità e flessibilità. Oltretutto il grande numero di librerie disponibili e la semplicità con cui si può utilizzare tale linguaggio di programmazione costituiscono due punti di forza per lo sviluppo di applicazioni molto articolate.
Il framework è definibile come un’architettura di supporto sul quale si può realizzare un software. La sua implementazione risulta di fondamentale importanza perché facilita la scrittura del codice, risparmiando allo sviluppatore la riscrittura di quest’ultimo per richiamarne parti di esso. Per lo scopo si è optato per l’utilizzo di PyTorch, framework open source di machine learning elaborato da Meta AI.
Per implementare modelli di machine learning efficienti è necessaria una potenza di calcolo non indifferente che spesso le comuni macchine commerciali non riescono ad offrire, specialmente se si pensa all’utilizzo di dataset composti da un numero enorme di elementi e di dimensioni elevate. Per questo motivo si è scelto di assemblare i modelli di apprendimento automatico nell’ambiente di calcolo di Colaboratory, meglio noto come Google Colab. Si tratta di uno strumento gratuito offerto da Google che permette di scrivere in Python direttamente da browser e di eseguire il codice online (sul cloud) sfruttando i comodi Jupyter Notebook, ovvero documenti interattivi nei quali si può scrivere il codice e suddividerlo in celle.
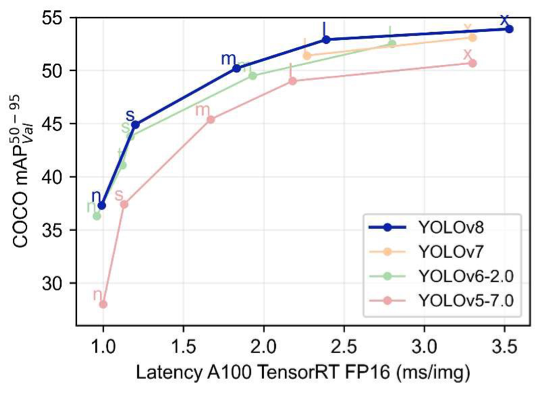
Per l’occasione si è scelto di implementare come architettura di base dell’addestranda rete neurale convoluzionale la famiglia di modelli di ultima generazione YOLOv8, scelta per la semplicità di utilizzo, per la sua versatilità e per le elevate prestazioni contro un onere computazionale decisamente inferiore rispetto al resto degli altri modelli di object detection (fig. 3). I valori mAP (mean average precision) presenti sull’asse delle ordinate vengono utilizzati per misurare la precisione media del modello nell’individuare gli oggetti nell’immagine, riferendosi a risultati ottenuti sul dataset COCO (un dataset ad ampia scala contenente oltre 330mila immagini e sviluppato da Microsoft), mentre i valori di Latency A100 Tensor RT FP16 presenti sull’asse delle ascisse indica la latenza del modello su una GPU Nvidia A100 utilizzando TensorRT (una libreria di accelerazione di inferenza) con precisione a 16 bit.
Per leggere l’articolo completo acquista il numero 20 della rivista Lo Strutturista.
Per essere sempre aggiornato e leggere contenuti inediti abbonati alla rivista Lo Strutturista – La prima rivista per gli strutturisti italiani.











La rete degli strutturisti
Entra a far parte del più grandi network di strutturisti italiani.


La rivista “Lo Strutturista”
Trimestrale cartaceo disponibile in abbinamento per la formazione del progettista
